Natural-Language Video Scene Search
A semantic video retrieval system that indexes scene-level content from media archives and returns the most relevant moments from a natural-language query.
Visit repositoryMaking video archives searchable
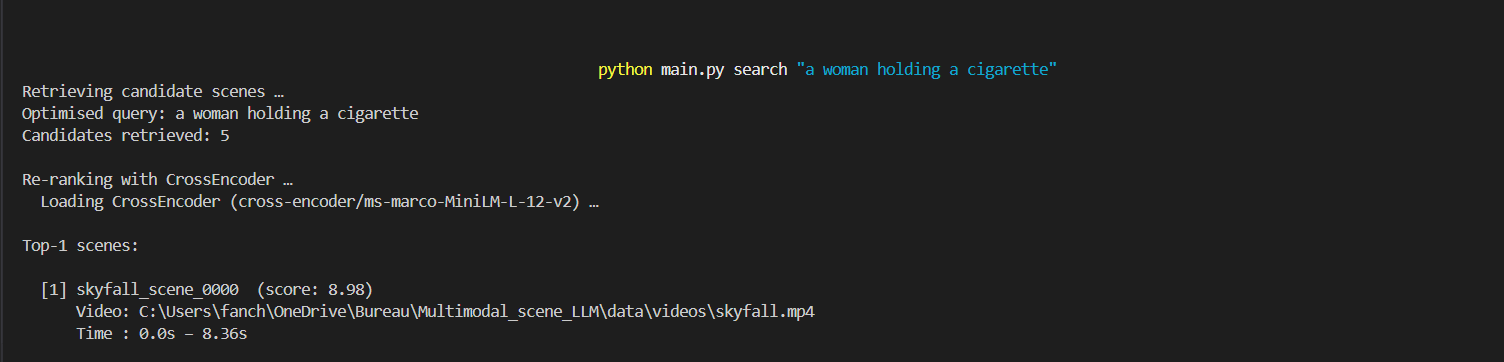
This project was designed to help turn large video archives into searchable assets. Instead of manually browsing long recordings, the goal was to let users retrieve relevant video moments directly from a natural-language query.
To achieve this, the system works at the scene level rather than at the video level, making retrieval more precise and better suited to real editorial or media workflows.
From raw video to scene-level indexing
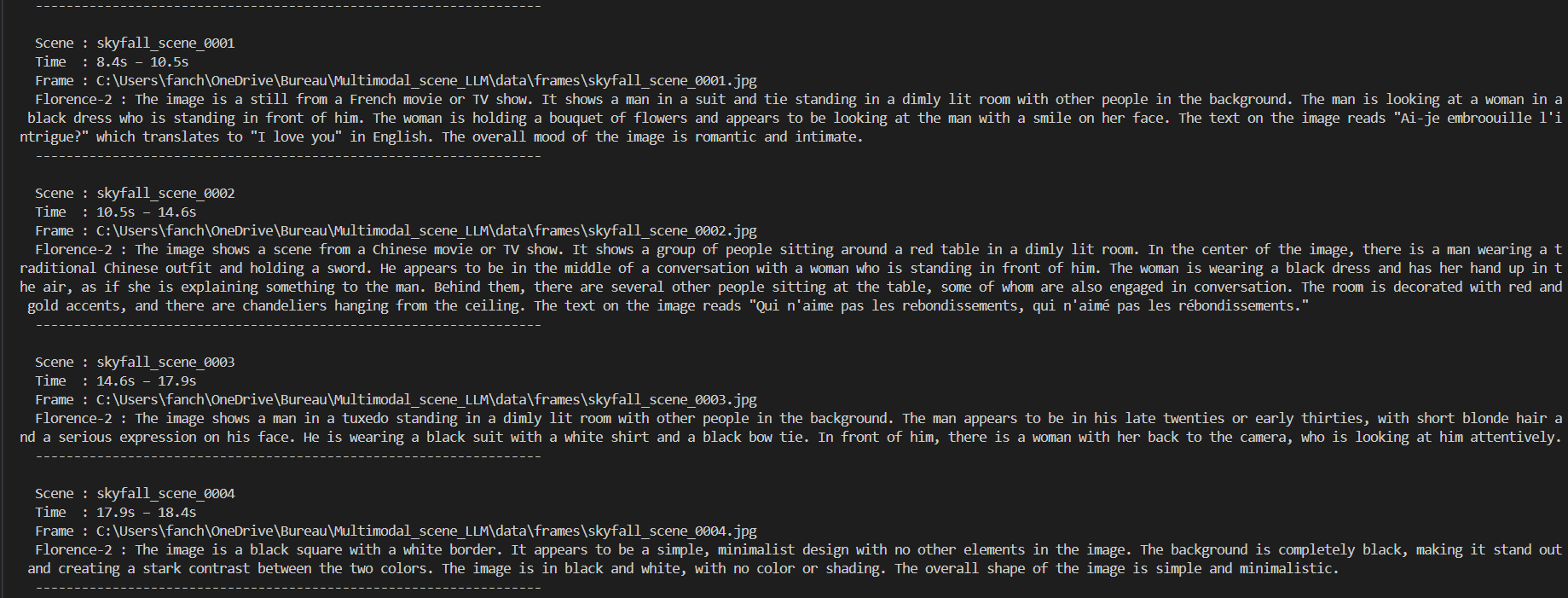
The first step of the pipeline was splitting long videos into meaningful scenes using PySceneDetect. This made it possible to move from coarse video metadata to smaller, more semantically coherent units of content.
Each scene was then processed independently, creating a structured foundation for search and retrieval. This scene-based approach improves both relevance and usability, since users are typically looking for specific moments rather than full videos.

Describing scenes with multimodal representations
Once scenes were extracted, the system generated visual descriptions using Florence-2, an open-source vision model capable of producing rich scene-level captions. These textual representations were then embedded and stored in ChromaDB to support semantic search.
A practical search engine for media archives
The final system demonstrates how multimodal models, vector search, and ranking techniques can be combined into a practical retrieval engine for archived video content.
By indexing scenes instead of full videos and combining semantic retrieval with re-ranking, the project provides a more efficient way to surface relevant moments from large media collections.
Beyond the retrieval task itself, the project also served as an exploration of multimodal AI pipelines, covering scene detection, visual captioning, embeddings, vector databases, and ranking strategies in a single end-to-end system.